Web前端路由
SPA和MPA
-
SPA:单页面应用
-
MPA:多页面应用
关于单页面应用和多页面应用的区别:

简而言之,传统的网站大多都是MPA,每个页面独立开发,页面直接的切换往往通过超链接来打开一个新的页面,每次打开新的页面都需要重新加载;与之相对应的SPA单页面应用,主要是在组件化和模块化开发成为潮流之后诞生的,往往是在一个页面内通过加载不同的组件来实现类似于页面的切换,这里不需要打开新的标签页,也就是说很多网页资源不必重复加载。
当然,目前还有一种微前端开发模式,可以在一个前端框架中嵌套其他的开发框架,可以实现完全不同的多个页面嵌套。
路由原理
单页面应用的一个核心就是要利用浏览器的url机制来判断用户当前的访问路由,来控制网页组件的渲染,同时也能使浏览器在不打开新的标签页或者不刷新页面的前提下进行页面、组件的切换和判别。
原理一:基于Hash实现

hash变化也成为锚点变化,特点就是浏览器的url地址中有一个#,我们将页面、组件的路径放在锚点之后,在这种情况下,浏览器是不会对#后面路径的变化而刷新网页。
hashchange事件也是浏览器提供的一个事件,我们通过监听这个事件的变化来控制组件的切换。
但是缺点是,#后面的部分事实上是无法被后端应用所获取的,
目前主流的浏览器都是支持hash模式切换的
原理二:History API实现

同样是利用浏览器提供的History API,浏览器提供了pushState/replaceState方法来改变url,同时也控制浏览器不会主动进行页面的跳转和刷新。我们还可以基于popState获取浏览器的状态。
路由实现
以Hash模式为例,最原生的实现方式:
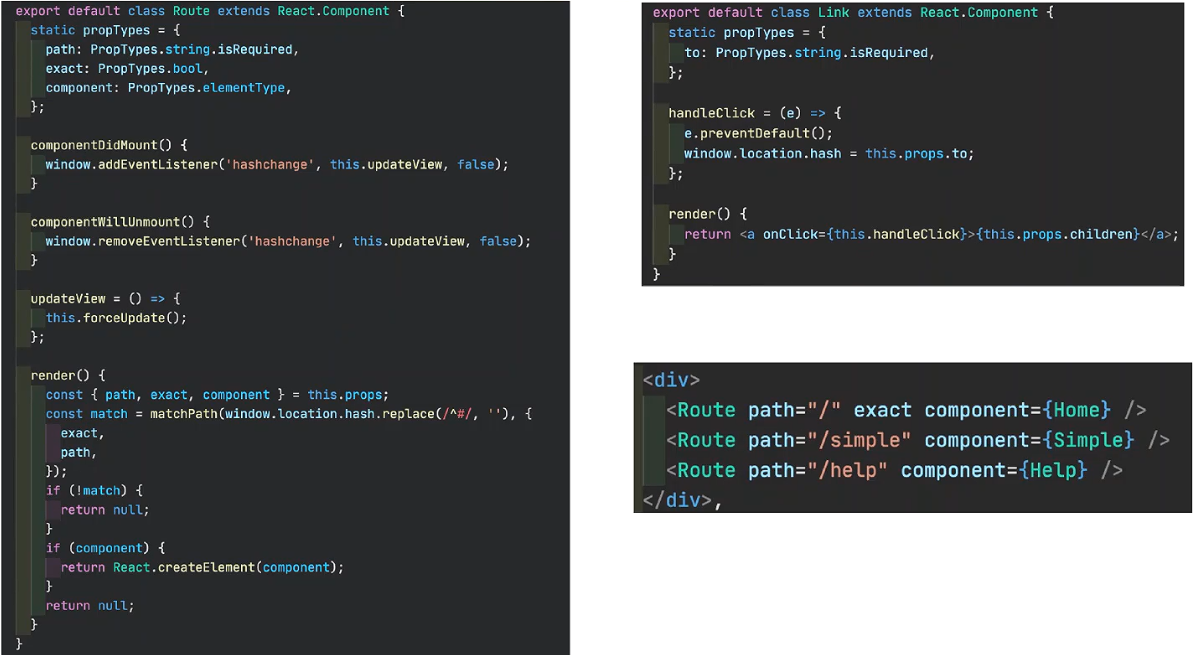
我们通过一个Route组件来判断当浏览器触发了HashChange事件的时候,通过matchPath方法获取#后的内容来判断是当前访问的路径与我们定义的路由是否一致,一致则渲染出组件,否则就不渲染。这样我们就可以实现在不同的路径下渲染不同的组件。
这种情况下,我们实现页面跳转的传统方式a标签将不适用,因为我们不是要改变地址的路径,而是改变hash部分,这里封装了一个组件来实现一种类似a标签的功能,这个组件的功能是改变url的hash部分,来达到页面跳转的功能。
这两个封装的组件(Route和Link)就实现了hash路由的管理和切换,而我们主页面的内容中只是调用了Route组件,其中path属性便是页面(组件)的路由。
而且可以发现,主页面Route属性中的path仅仅包含着相对地址,页面(组件)的完整地址并不包括,这也就是组件化开发的一个优点。也就是说,我们这里只关注相对地址,至于使用Hash模式还是History API来实现路由管理,主页面这里并不关心,相当于将路由的管理部分隔离了出来,也方便我们后续开发中对路由管理模式的修改。
React-router
之前原生的路由实现方式仅仅适用于一些很简单的项目,如果在生产环境中要对大量的组件和页面进行路由管理,我们就需要一个更完整的路由管理工具。尤其是当涉及到路由的权限管理已经一些动态路由管理的时候,使用React-router这个库将使得我们的开发更加容易。比如我们需要用一串特征参数和甚至权限参数整合的路由来表示某论坛一篇帖子的路径,又比如某个页面的路由地址是一串加密的包含用户信息的路由……诸多情况我们都可以使用React-router来实现。
具体的react-router API可以自行去官网文档中查询。
react-router核心组件
分为三个层次:

最外层有一个容器来判断路由切换的两种模式,可以对浏览器的兼容性进行判断,选择合适的路由方式。
第二层是路由的定义,
第三层是路由的跳转。
使用React-router组件:我们只需要安装这个依赖,然后再需要的页面中应用即可。
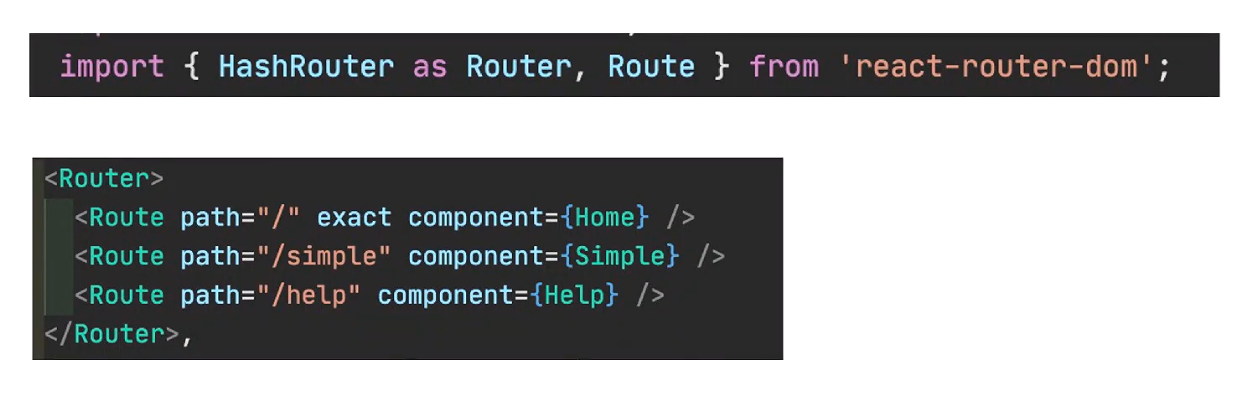
小结
在以上的例子中,我们其实探究了路由管理的底层逻辑和浏览器两种不同的路由实现模式hashRoute和browserRoute。在实际的生产开发中,很多脚手架已经将react-router封装了进去,例如Ant Design Pro。